Scrolling down LinkedIn, I see a new AI startup founder every other post. I used to chuckle whenever I’d see a “Prompt Engineer” role — what’s so hard about writing an LLM prompt that requires it to be a dedicated job? The comments on new startups are a back and forth of excitement and critics deeming it another “wrapper”. Looking back now that I’ve worked on my own product, I couldn’t disagree with that label more — but I understand why it might appear to be so.
Before LLMs came about as a service, “AI/ML” typically used to mean that companies or products would create their own models from scratch with proprietary data specialized in a specific task. That could be a computer vision model that grades how nice your jumpshot is, or a recommender system that picks movies based on what you like. The strategic advantage in most cases was the underlying model itself. That paradigm has completely shifted now.
After building CerebroAI (a chatbot designed to retrieve basketball statistics and perform analytics on the world’s largest box score database), I’ve truly realized how much complexity goes into creating a successful LLM system. It’s been a back and forth of collaboration with the folks over at Google Cloud and Vertex AI to create a system that is optimized for speed, accuracy, and function.
The first piece of the puzzle is coming up with a reliable evaluation strategy for the service. Without a way to measure whether the model’s responses are improving, changes could regress the model. How do you measure the accuracy of a system with an infinite number of inputs and outputs? Approaching this task really depends on what the system is intended to do — is it meant to prioritize accuracy over depth? Is latency a major concern? Is there a definitive right or wrong outcome to the response? These types of questions help narrow down the kind of benchmarks, metrics, and testing data used to evaluate the system.
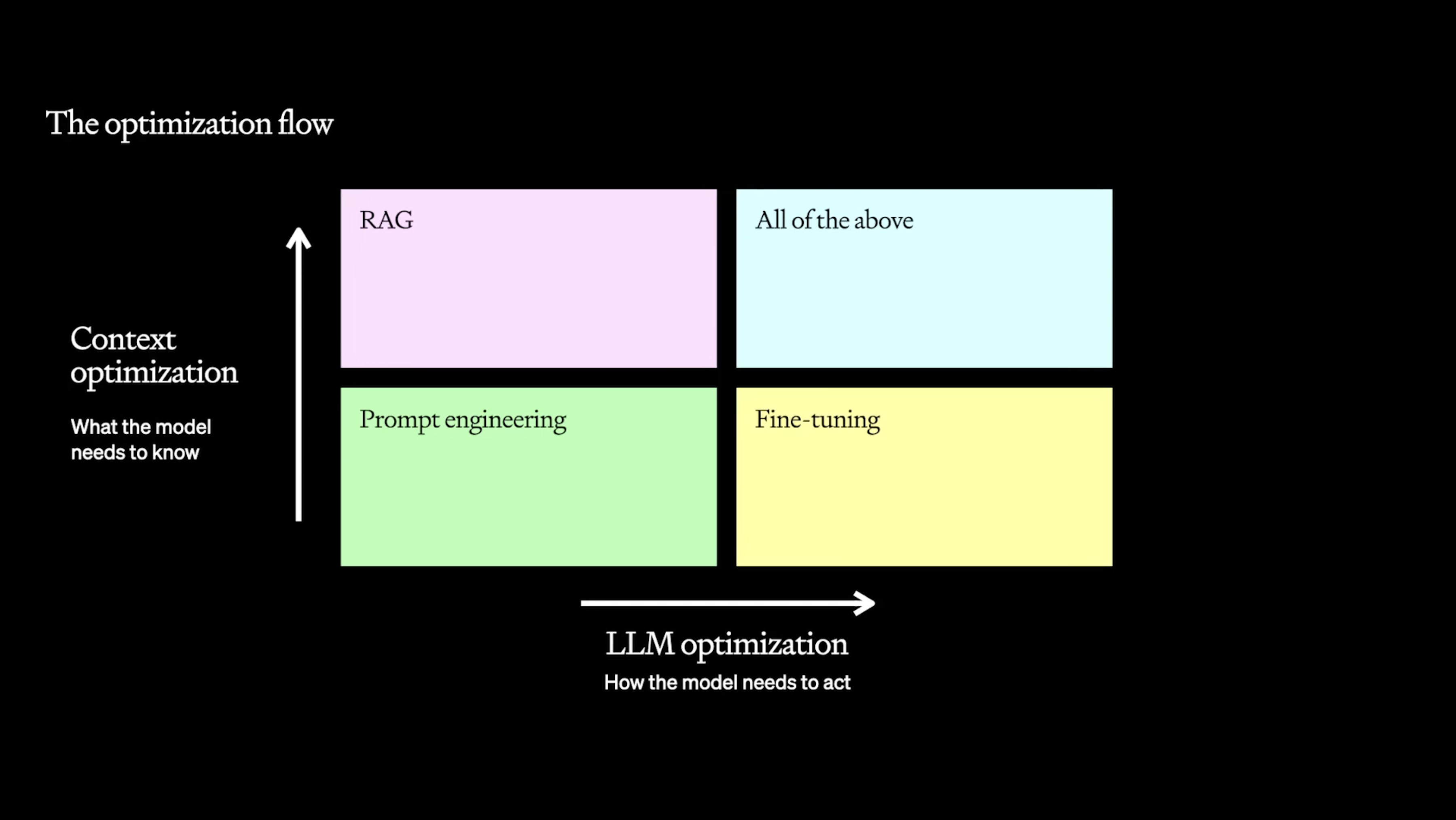
The next basic yet crucial step is prompt optimization. The easiest things to start off improving are the system and user prompts. Although it may seem easy to write, there are a lot of things that go into writing an effective prompt. It’s important to condense the information — a long prompt may cause instructions to get lost in the middle. The structure of the prompt drastically changes how the LLM will interpret instructions, and it needs to be well equipped to handle edge cases and guard railing.
Finally, there are a whole bunch of other techniques that determine how complex the system is. There could be RAG (Retrieval Augmented Generation) to reduce the prompt size while retaining information, tool calls that execute a SQL statement or visit a website, a graph of LLM calls to break down problems, an LLM router that determines what types of workflows to engage in, LLM cascading to optimize cost, etc.
With so many different ways to manipulate inputs to LLMs and call them for specialized tasks, calling a startup a “GPT Wrapper” just doesn’t make sense. A CPU isn’t considered a “transistor wrapper”. There’s a constant process of engineering and scientific reason that goes into creating a specialized LLM product. If there’s any sort of specialization that can improve LLM performance under a specific niche, it provides immense value over using a base model. With tech giants continuously improving the capabilities of their models, startups are forced to quickly adopt new paradigms of engineering to maintain their edge.